
KINEVA®
From computer vision to language models. Automatically trained, locally executed.
No model for your use case? KINEVA trains it. No data science team.
No model for your use case? KINEVA trains it. No data science team.
KINEVA is REBOTNIX's proprietary AI platform. Models are trained automatically and delivered production-ready, without manual labeling. Deployable on edge, in private datacenters, or in hybrid cloud environments.
No model for your use case? KINEVA trains it automatically. No data science team needed, no manual labeling.
Every model is optimized for NVIDIA Jetson and GUSTAV hardware. TensorRT-accelerated, under 8ms inference time.
CNN for detection. PCNN for sensor fusion. VLLM & LLM for language understanding. One platform, all approaches.
CNN is suited for image processing: detecting objects either as bounding boxes or pixel-accurate segmentation. Fast, precise, directly on the camera.
View CNN models →
PCNN starts with image processing and fuses sensor data directly into training. After training, the model detects objects from sensor data alone, without a camera.
View PCNN models →
KINEVA ONE understands images and talks about them. It describes scenes, detects anomalies, and generates reports automatically. Runs in real time, knows the time, and can act directly. Local, without cloud.
View VLLM models →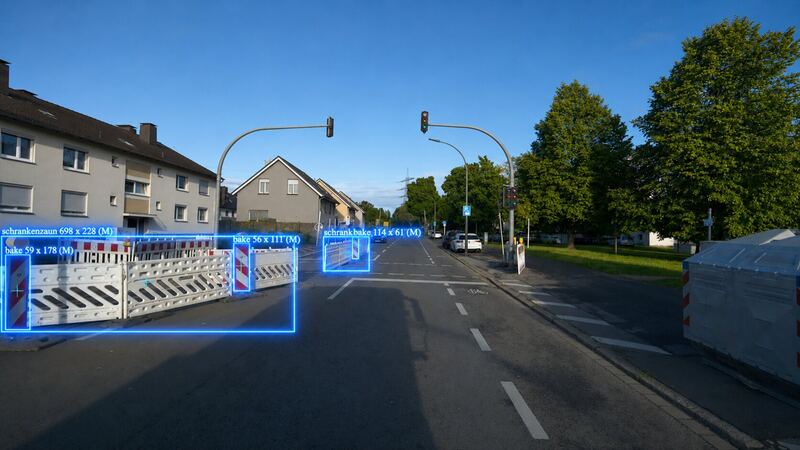
30 billion parameters. Every quarter up to 5 billion of them are retrained with current data from Smart City and Industrial.
KINEVA ONE runs on REBOTNIX Realtime Linux and understands time as a dimension. It knows how long a process has been running, when it should be done, whether it is overdue. Natively anchored in the operating system.
KINEVA ONE executes functions directly. Stop machines, trigger alarms, change sorting, send reports. Multi-interface: chat, email, VoIP, PLC, OPC-UA, Modbus. An agent that acts in the physical world.
multilingual
Production-ready REST API. Send image, get detections back. Free entry, scalable to enterprise.
Select models free on Hugging Face and GitHub. Download, fine-tune, deploy at the edge.
KINEVA trains models for your use case, even without existing training data. Talk to us.
Production-ready detection and classification models. CNN, PCNN, VLLM & LLM.
Convolutional neural networks optimized for real-time object detection and classification on edge devices.
Alle CSPCore- und CSPAttention-Blöcke sind proprietäre KINEVA®-Architektur · 5-Skalen-Erkennung ohne Anker · Stride 4–64
Accurate head and person counting in crowded scenes. Works from any camera angle, optimized for overhead, angled, and street-level perspectives.
Detects and reads license plates in real-time. Supports European plate formats. GDPR-compliant anonymisation mode available.
Detects illegal dumping in public spaces using camera feeds and GPS geolocation. Automatic dispatch for municipal waste management.
Classifies waste into bulky waste, household waste, textiles, and hazardous materials. Automated sorting and compliance monitoring for recycling.
Detects and classifies passenger cars and commercial trucks. Optimized for traffic monitoring and logistics applications.
General-purpose 80-class baseline. Use as a starting point for transfer learning or deploy directly for rapid prototyping.
Vandalism detection fused with GPS coordinates for automatic dispatch. Distinguishes art installations from illegal graffiti.
Road sign detection with GPS-tagged geolocation. Automatically maps sign positions and condition for infrastructure monitoring.
Head-based face anonymisation, works even when faces are turned away or partially covered. GDPR-compliant, on-device processing.
Physical-world CNNs that fuse camera data with WiFi, GPS, satellite, and sensor signals at the tensor level.
Detects and tracks people using WiFi probe signals, without a camera. Trained with visual data, runs entirely on WiFi sensors. Privacy-compliant.
High-precision GPS positioning by fusing camera data with GPS signals. Delivers RTK accuracy without RTK hardware.
Vision-language and large language models for scene understanding, report generation, and industrial reasoning.
Visual language model that describes industrial scenes, identifies anomalies, and generates inspection reports from camera feeds.
LLM that generates structured maintenance reports from detection data. Integrates with existing municipal and enterprise workflows.
Every KINEVA model is trained to meet EU AI Act requirements. Documented data provenance, bias testing, traceable decisions. Risk management per Article 9, technical documentation per Article 11.
Auditable training pipeline, versioning and edge deployment without cloud dependency. KINEVA is suitable for certifications in critical infrastructure: energy, water, transport, industry.
KINEVA trains custom models for your specific use case. You need no own data and no GPU resources, KINEVA handles that for you.